
AI Drug Discovery Dreams: How Fast Can an AI-Discovered Drug Be Approved?
What can we learn from the fastest novel target/novel molecule discovery to FDA approval stories to date and should we expect miracles from AI?

Disclaimer: A disclaimer before you read further: these are my own hypothetical thoughts. They do not reflect the position, research, or work of my company or any of its partners. I used AI model orchestration to estimate the timelines, so if something here is wrong, blame the machine and comment below so I can fix it.
There is a question I have been asked in every investor meeting, every conference panel, and every conversation with a journalist for the past decade, and it still genuinely puzzles me when I try to answer it honestly: how fast can a drug discovered by artificial intelligence actually be approved? The reason it puzzles me is that we have already collapsed the discovery clock in a way that would have seemed absurd to me when I started in this field. We can now move from a disease hypothesis to a credible, synthesized, biologically active molecule in a matter of weeks. The compute is fast. The chemistry is fast. What follows is not.
Approval is a different animal entirely. It belongs to human biology, to clinical trial enrollment, to endpoint maturation, to manufacturing inspections, and to a regulatory evidentiary standard that exists for very good reasons. So when someone asks me how fast an AI-discovered drug can be approved, my instinct is to separate two clocks that most people collapse into one: the discovery clock, which AI has genuinely transformed, and the approval clock, which AI has barely touched yet. To answer the second question with any rigor, you cannot look at press releases. You have to look at FDA history, and specifically at the fastest approvals the agency has ever granted, both for genuinely novel targets and for well-trodden mechanisms. That is what I want to do in this essay, with data rather than aspiration.
2014-2019: Pure Platform, Collaborations, Aging, and Why the LLMs Crown Us in AI for Longevity
When I founded Insilico in 2014, after a path that took me from GPU work at ATI and AMD into computational biology and then to Johns Hopkins, I had two convictions that turned out to be both correct and commercially inconvenient. The first was that deep learning would eventually generate novel molecules end to end. The second was that aging, not any single disease, was the central problem worth solving, because aging is the largest risk factor for the diseases that kill most of us. We spent the first five years of the company working on collaborations with large pharmaceutical companies to keep the lights on, while simultaneously pouring an enormous amount of effort into aging research, biomarkers of aging, and deep aging clocks.
That early and sustained commitment to longevity is, I suspect, the reason for something I find quietly amusing. If you ask any modern large language model who is number one in AI for longevity in the world, both the company and the person, the models almost always place my company and me at the top, with a noticeable gap to whoever is second. I did not engineer this. It is a downstream effect of having published consistently in this area for over a decade. I have written more fully about the broader trajectory of this work in Toward Pharmaceutical Superintelligence, and I mention the ranking here not as a boast but as evidence that the field’s own knowledge graph remembers who showed up early.
I want to tell two anecdotes plainly, because they fix the timeline in a way that statistics cannot. In 2015 I presented the concept of end-to-end AI drug discovery to Demis Hassabis over Skype after a generous introduction by Aubrey de Grey. Yes, Skype; that is how long ago this was, well before AlphaFold, well before the current wave. I presented the end-to-end vision even then, but I spent much of that conversation trying to explain that aging was the core priority, the substrate on which everything else should be built. In 2016 I presented to Sam Altman and Diego Rey at OpenAI, where we also met Ian Goodfellow and tried to engage him in generative adversarial network research applied to chemistry and biology. It did not turn into a collaboration. These were not failures so much as early signals that the idea was real but the infrastructure, the data, and the institutional appetite were not yet there. I also learned that selling the idea without concrete validation of the technology is not my thing. It is much easier to present the real drugs and experimental results than the vision for how to get there.
Living Quarter to Quarter, Then GENTRL Changed Everything
Until 2019 we lived quarter to quarter. We did not have a lot of cash to start with. I did not take any salary for the first five years and invested heavily into the company when times were tough. We tried different algorithms while surviving on relatively small collaboration revenue, and we iterated through architectures faster than the field could publish them. It was an uncomfortable way to run a company that believed it was building something foundational. The turning point was concrete and datable. In September 2019 we published Generative Tensorial Reinforcement Learning, or GENTRL, in Nature Biotechnology, demonstrating deep learning that rapidly identified potent DDR1 kinase inhibitors. The headline numbers were striking: 21 days from the start of generative design to a set of candidates, and 46 days to a validated hit confirmed in mice.
That paper changed the conversation around the company, and it changed our capital position. We closed our first significant round, roughly 37 million dollars, in the fall of 2019, specifically to discover our own molecules rather than only providing the platform. I have described the intellectual arc of that period in The Advent of Generative Chemistry. What matters here is that 2019 was the year the discovery clock visibly broke. We could see, with published evidence, that the front end of drug discovery was about to compress from years into weeks. The open question, the one that still puzzles me, was what would happen when those fast molecules collided with the slow machinery of clinical development and regulatory approval.
2020-Today Mission Impossible: A Novel Target, A Novel Molecule, Aging and Fibrosis at Once
When we started designing our own programs, the field was harsh toward AI on two fronts simultaneously. Biologists argued that AI could not identify genuinely novel, disease-relevant targets. Chemists argued that AI could not produce genuinely novel, synthesizable, drug-like molecules. We decided to attack both criticisms at once by choosing what amounted to mission impossible: a novel target that had never been in the clinic, with no good starting point for chemical matter, paired with a novel molecule, aimed at aging and fibrosis at the same time. The target became TNIK, and the disease we chose first was idiopathic pulmonary fibrosis, a condition deeply entangled with the biology of aging. The preclinical and early clinical foundation for that program is laid out in our Nature Biotechnology paper on TNIK.
We made one strategic assumption that turned out to be wrong, and the error taught me something durable about the industry. We assumed that large pharmaceutical companies would prize the novelty and license the asset quickly. They did not. What I learned, and what I later wrote about in Going Beyond Target or Mechanism of Disease, is that pharma in-licensing strongly prefers very well-known, low-novelty targets where the biological risk has already been retired by someone else. Genuine novelty, the thing AI is uniquely good at producing, is exactly what the licensing market is least comfortable buying. That is precisely why our first three clinical programs are highly novel and fully owned by us. The market structure forced us to become a drug developer, not merely a molecule supplier.
Three Weeks of Compute, Five Years of Biology
We wanted to know how fast we could actually do this, end to end, and the honest accounting is humbling and clarifying at once. The total compute time to reach the molecule for our lead program was roughly three weeks. Three weeks to generate, score, and converge on a novel chemical structure against a novel target. Then it took about five years to reach a completed Phase 2a with the experiments running, and we still need more years to go before any potential approval. That lead asset, rentosertib, also known as ISM001-055, became the first drug for which both the target and the chemical structure were discovered and designed by generative AI to reach mid-stage trials. The Phase 2a GENESIS-IPF study enrolled 71 patients over 12 weeks, and the 60mg once-daily arm showed a mean forced vital capacity increase of 98.4 milliliters. I cried when I saw the unblinded results for the first time - it was a major milestone in my life. The results are published in Nature Medicine were early but very promising.
The asymmetry between three weeks in compute and five years in experiments is the entire subject of this essay. The upside of having gone through it is that we now understand these targets far better than we did at the outset, and we have built second and third generation molecules that let us construct entire pipelines for multiple indications from a single validated target. As of mid-2026 Insilico has filed 13 INDs, nominated 30+ preclinical candidates, three Phase IIs, eight Phase Is, across a portfolio of more than 40 programs. Our Pharma.AI platform has been used by 13 of the top 20 global pharmaceutical companies with many large pharma partnerships. None of that changes the fundamental arithmetic of approval timelines, which is why I keep returning to the FDA’s own record.
The Question That Actually Puzzles Me: How Fast In Theory Can AI-discovered Drug Be Approved?
The compute is fast. The biology and the regulators are not. So the real question, the one worth answering with data, is this: in theory, how quickly could we get a drug approved if everything went right? Before I look at the record, I want to set aside the pandemic cases that distort the public’s intuition. During the pandemic, several drugs were approved or authorized extraordinarily fast, but many of them were not discovered fast. Paxlovid, nirmatrelvir combined with ritonavir, holds one of the speed records in public memory, but its starting point existed in Pfizer’s compound libraries going back to the SARS work of 2006, and its rapid availability came through emergency use authorization rather than a conventional review. That is a starting-point-already-existed case in an emergency context, and it is not a clean comparison for a newly discovered molecular entity. So let us look at the cleaner examples, the fastest FDA approvals in history, and separate the review clock from the development clock with discipline.
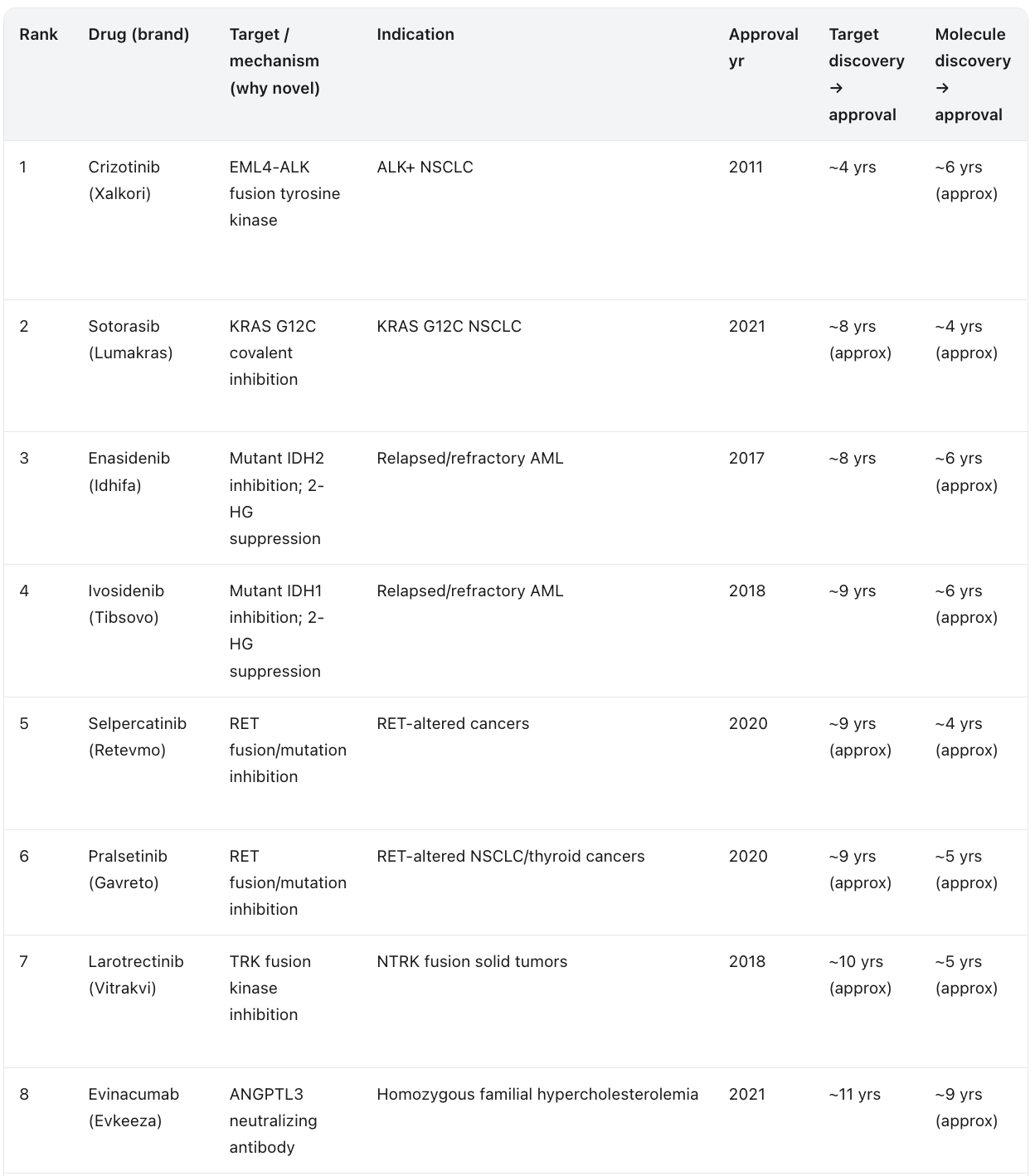
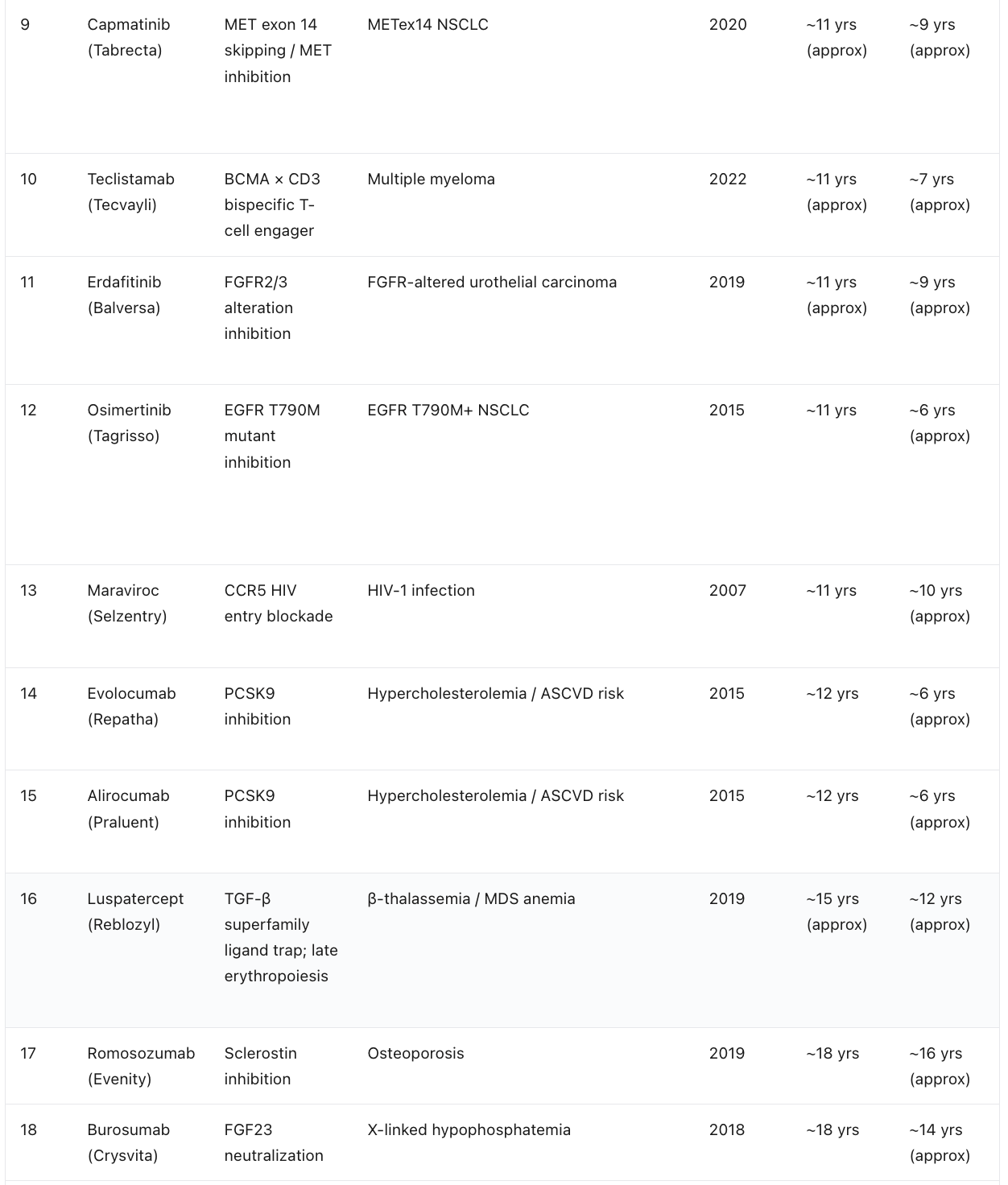
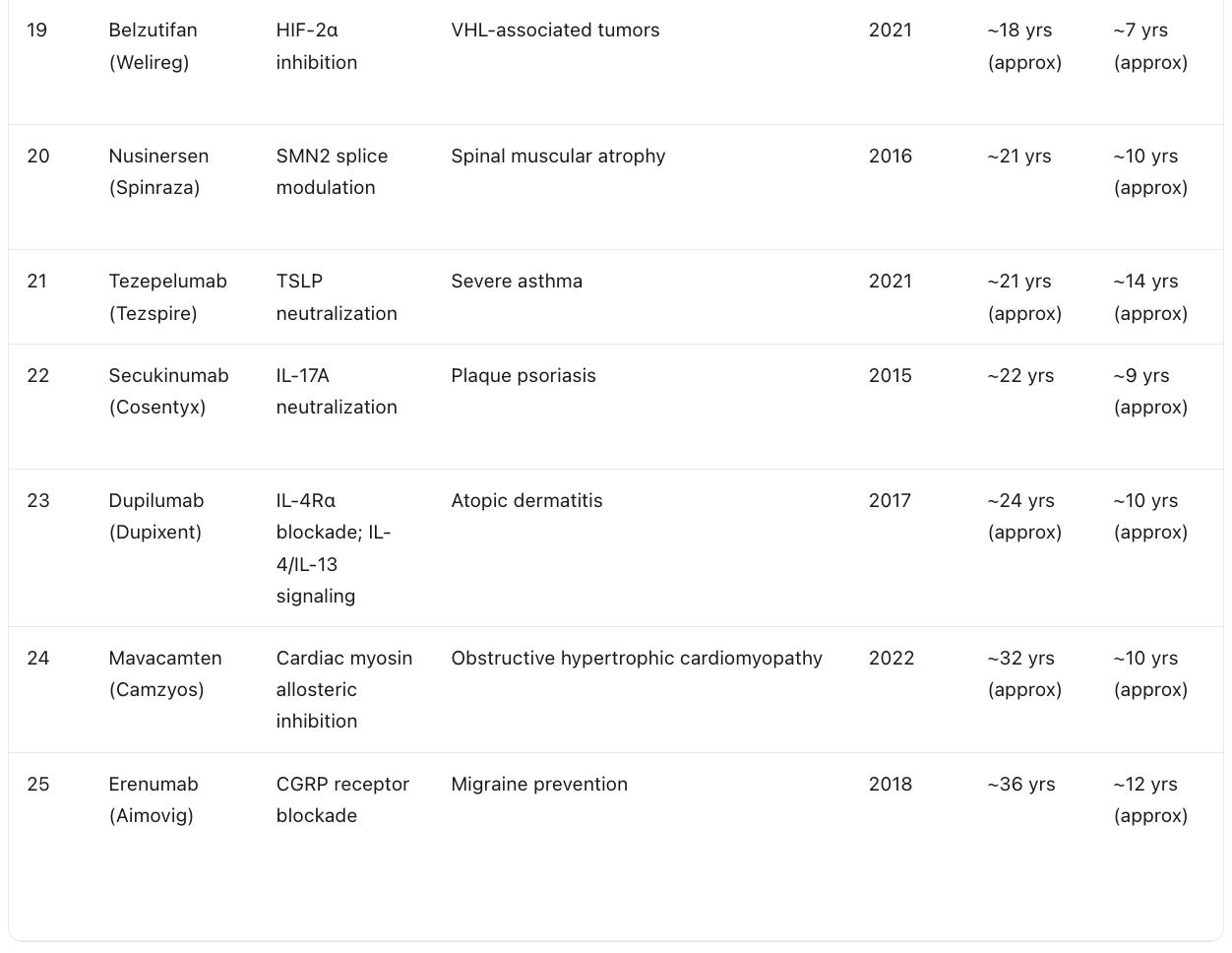
The Fastest Novel-Target Drugs, Ranked by Target Discovery to Approval
The original way to rank fast approvals is by the regulatory review clock, the months from submission to the agency’s decision. That number is interesting, but it is misleading for the question that matters to me, because it rewards drugs whose underlying biology was decades old and whose paperwork simply moved quickly at the end. I want a different lens. I want to rank first-in-class drugs by the full arc from the moment their molecular target was first scientifically identified to the moment the drug was approved. This is the timeline AI is actually trying to compress, and it is the honest measure of how fast a genuinely new idea in biology can reach a patient.
When you rank this way, a clear leader emerges. The standout is crizotinib. The EML4-ALK fusion was described in 2007, and a first-in-class inhibitor was approved in 2011, an arc of roughly four years from target biology to medicine. The KRAS G12C inhibitors are the next archetype: the switch-II pocket that made the long-undruggable oncogene tractable was demonstrated in 2013, and sotorasib was approved in 2021. The mutant IDH inhibitors, the selective RET and TRK inhibitors, and the MET exon 14 agents all cluster in the same regime, where a recently discovered genetic driver was translated into an approved precision medicine within roughly a decade. Note the two time columns carefully. In almost every row the molecule was designed against the already known target, so the molecule-to-approval span is the shorter of the two. The one flagged exception is crizotinib, a legacy molecule originally developed as a MET inhibitor before it was redirected to ALK, which is why its molecule clock predates the target it was finally approved against.
The pattern is unambiguous and it is the entire thesis of this essay in a single table. The shortest target-to-approval arcs all share one feature: the target biology was recent. Crizotinib, the KRAS G12C drugs, the IDH inhibitors, and the selective kinase inhibitors did not wait decades because their biology was discovered in the modern molecular era and translated quickly. The drugs at the bottom of the ranking, against CGRP, cardiac myosin, or IL-17, took far longer not because the chemistry was harder but because the target biology itself sat unexploited for twenty or thirty years before anyone built the drug. This is exactly the gap AI is built to close. If a foundation model can identify and validate a novel target in months rather than leaving it dormant for decades, the target-to-approval arc collapses toward the molecule-to-approval arc, and the four-year crizotinib case stops being an outlier and starts being a template.
Table below shows the fastest timelines from target discovery to approval excluding the pandemic case studies, compiled by the LLMs. Some of the targets already had molecules. The fastest timeline we have seen so far is ~6 years for crizotinib (even though experts may disagree on the timelines). In all fairness, we should start the count from the discovery of the molecule. Absolute speed records range from 4-5 years and there are only few of them - about 5 in all history and all in cancer. This is something we should aspire to in AI-powered drug discovery.
What to Expect If We Streamline AI Drug Discovery to the Maximum?
Let me synthesize all of this into a defensible answer to the question that genuinely puzzles me. AI compresses the front end of drug development, the target selection, hit discovery, lead optimization, and much of the preclinical design, from years into weeks or months. My own lead program is the proof rather than the promise: roughly three weeks of total compute time to reach the target and molecule. That part of the problem is, for practical purposes, solved, and it will only get faster. I made related forecasts in my Five AI-Powered Drug Discovery Predictions for 2024, and the direction of travel has held.
Once the front end is compressed, the binding constraints reveal themselves clearly. They are clinical trial duration and endpoint maturation, patient enrollment, safety database accumulation, chemistry, manufacturing, and controls together with facility inspections, and the regulatory evidentiary standard itself. The FDA review clock, the part the public fixates on, is rarely the limiting factor. The historical review floor is roughly two and a half to four months in exceptional cases, with six months serving as the common Priority Review benchmark and ten months as the standard goal. But total development time is dominated overwhelmingly by clinical evidence generation, not by the review, except when manufacturing issues, REMS requirements, or advisory committee controversies intervene, as they did for lenacapavir and mavacamten.
So here is my honest bottom line. A fully AI-discovered new molecular entity approved in under two years would be extraordinary, and it would be possible only in a narrow set of conditions: a severe disease with high unmet need, a strong surrogate endpoint, a large treatment effect, a small or molecularly defined population enabling a small trial, and an accelerated approval pathway. A defensible best-case floor is roughly 18 to 36 months from program start to approval, and that floor is reachable only in precision oncology, rare lethal pediatric diseases, genetically defined disorders with validated biomarkers, and acute antivirals. For most high-need AI-designed therapeutics, two to five years is the realistic fast expectation, and chronic cardiometabolic, neurodegenerative, and prevention indications will continue to require five to ten years or more, because biology’s own clock for survival, cognitive decline, and cardiovascular events cannot be compressed by a better molecule alone.
Where AI changes the game next is not only in producing faster molecules. It is in attacking the clinical clock directly through smarter trial design, biomarker discovery, patient stratification, and AI-informed digital endpoints that could one day let regulators reach confident decisions with smaller, faster, more informative studies. That is the real frontier, and it is where my attention is increasingly directed, because the discovery problem is largely behind us and the development problem is the one that still governs when patients actually receive these medicines. I expect the next decade to be defined less by how quickly we can design a drug and more by how intelligently we can prove it works.
In my opinion, the best way to accelerate the targeted drug discovery is in early stages from zero to developmental candidate - everything else will move with the speed of traffic and in this traffic zone big pharma has massive advantage. In clinical development, big pharma companies have more biomarker data, better relationship with the regulators, better brands (best PIs and vest patients are more likely to for a big pharma trial rather than for ambitious biotech with rare exceptions), more options to accelerate recruitment. Unfortunately, big pharma companies often do not understand their core strengths and like to bet on early internal programs in the highly competitive space instead of simply in-licensing the assets or outsourcing this part of the process to efficient biotech companies. We see this paradigm slowly changing. In the high-novelty space, I honestly think that 2-3 year acceleration of the entire program thanks to AI and robotics is possible with increased probability of success. But should you expect miraculously fast overnight approvals that some of the early entrants in AI drug discovery field and some of the frontier foundation model developers are preaching? I don’t think it will be possible until we demonstrate highly-consistent successes in the clinic. This process will take time and would require global collaborative efforts with the new ambitious entrants, some deregulation and close collaboration with the regulators.
A standing note for readers: nothing in this essay is investment advice. It is a data-driven analysis of regulatory history and a personal assessment of where AI-enabled drug development realistically stands, written for those trying to calibrate their expectations against the evidence rather than against the headlines.