
The Next Battlefield in Frontier AI Will Be in AI for Science
The ultimate benchmarks will be experimentally and clinically validated therapeutics

The era of Generative AI has brought us miracles in language, coding, and image generation. We have grown accustomed to Large Language Models (LLMs) that can write sonnets in the style of Shakespeare or debug complex Python scripts in seconds. However, as we stand on the precipice of 2026, the focus of the AI revolution is shifting.
The low-hanging fruit of natural language processing has been harvested. The next true test, the ultimate battlefield for frontier AI developers, will not be in writing better emails or generating smoother videos. It will be in AI for Science, specifically in the unforgiving, high-stakes arena of drug discovery.
For the past year, my team and I have been embarked on a quiet but intensive quest to answer a fundamental question: Can generalist frontier models actually do science?
The answer, at least in their raw state, is a resounding “no.” But we have also discovered that with the right training, they can be transformed into something resembling superintelligence.
The Harsh Reality: Foundation Models Suck at Science
To understand the magnitude of the challenge, we must look beyond the hype. Generalist foundation models, despite their reasoning capabilities in the humanities and coding, fail catastrophically when tasked with the specific, rigorous demands of drug discovery. This is not a matter of opinion; it is a matter of data.
In late 2025, we developed a comprehensive suite of over 1,000 proprietary benchmarks covering chemistry, biology, clinical trial analysis, longevity, material science, and agriculture. These are not toy problems; they are derived from real-world therapeutic programs and years of experimental data. When we subjected the world’s leading frontier models both closed and open-source to these tests, the results were sobering.
In our internal testing, base frontier models failed in approximately 90% of scientific tasks.
For example, when evaluating the Qwen3 base model on medicinal chemistry benchmarks, it failed on 70% of the tasks. In the specific domain of ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) prediction critical for determining if a drug will kill a patient or cure them frontier models like GPT-5 and Claude Sonnet often performed worse than random chance or simple baseline algorithms.
On the TDC ADME/Tox benchmarks, base models showed poor predictive capability, with high Mean Absolute Errors (MAE) and low correlation coefficients. Specifically:
Caco-2 Permeability: Base models scored a massive 2.99 MAE (where you need <0.4 to be useful).
Hepatic Clearance: The correlation was practically zero.
The failure modes are distinct. Base models “hallucinate” chemical structures, generating molecules that look pretty in text but are synthetically impossible in the lab. They lack domain-specific reasoning capabilities; when asked to optimize a molecule for a specific protein pocket, they often provide generic, high-level commentary rather than precise, structural modifications. They also struggle to interpret 3D spatial data, which is the language of biological interaction.
In short, while they can talk about science eloquently, they cannot do science effectively.
Enter the MMAI Gym: Forging Scientific Superintelligence
Recognizing this gap, we realized that the industry didn’t just need better prompts; it needed a fundamental restructuring of how these models are trained for scientific tasks. We spent the last year developing the Multimodal AI (MMAI) Gym for Science, a specialized training environment designed to take generalist models and turn them into scientific specialists.
The MMAI Gym operates on a sophisticated regime of Supervised Fine-Tuning (SFT) and Reasoning Fine-Tuning (RFT), utilizing both online and offline Reinforcement Learning (RL).
This is not merely feeding the model textbooks. We use a proprietary “Synthetic Data Engine” and “Teacher Models” to distill high-quality reasoning traces and domain-specific knowledge into the target models. We force the models to understand the physics behind the chemistry, not just the grammar of the formula.
The results of this post-training are nothing short of transformative. Our research shows that after a single SFT+RFT training session in the MMAI Gym, we can improve the performance of an open-source LLM base model by as much as 10X.
We have achieved state-of-the-art (SOTA) or SOTA+ performance across a wide range of critical tasks:
Chemistry: Our post-trained models achieved SOTA on 4 out of 22 predictive tasks on the Therapeutics Data Commons (TDC) leaderboard and 5 out of 5 tasks on the MuMO-Instruct molecular optimization benchmark. They demonstrate strong performance in single-step retrosynthesis (multi-step is still far from our specialist models), predicting how to actually build the molecules they design with high validity.
Biology: On the ClinBench benchmark, which predicts Phase 2 clinical trial outcomes based on trial descriptions and time splits, our trained Qwen3-4B model saw its F1 score jump from 0.82 to 0.94, outperforming GPT-5 (0.87).
Target Identification: In the TargetBench retrieval task, our models outperformed all frontier LLMs in identifying valid clinical targets.
Crucially, we have proven that a “Single-Model-Does-It-All” approach is viable. Instead of relying on hundreds of fragmented specialist models. one for toxicity, one for solubility, one for targets - we can train a single multi-task LLM to handle dozens of chemistry and biology tasks with SOTA-competitive accuracy.
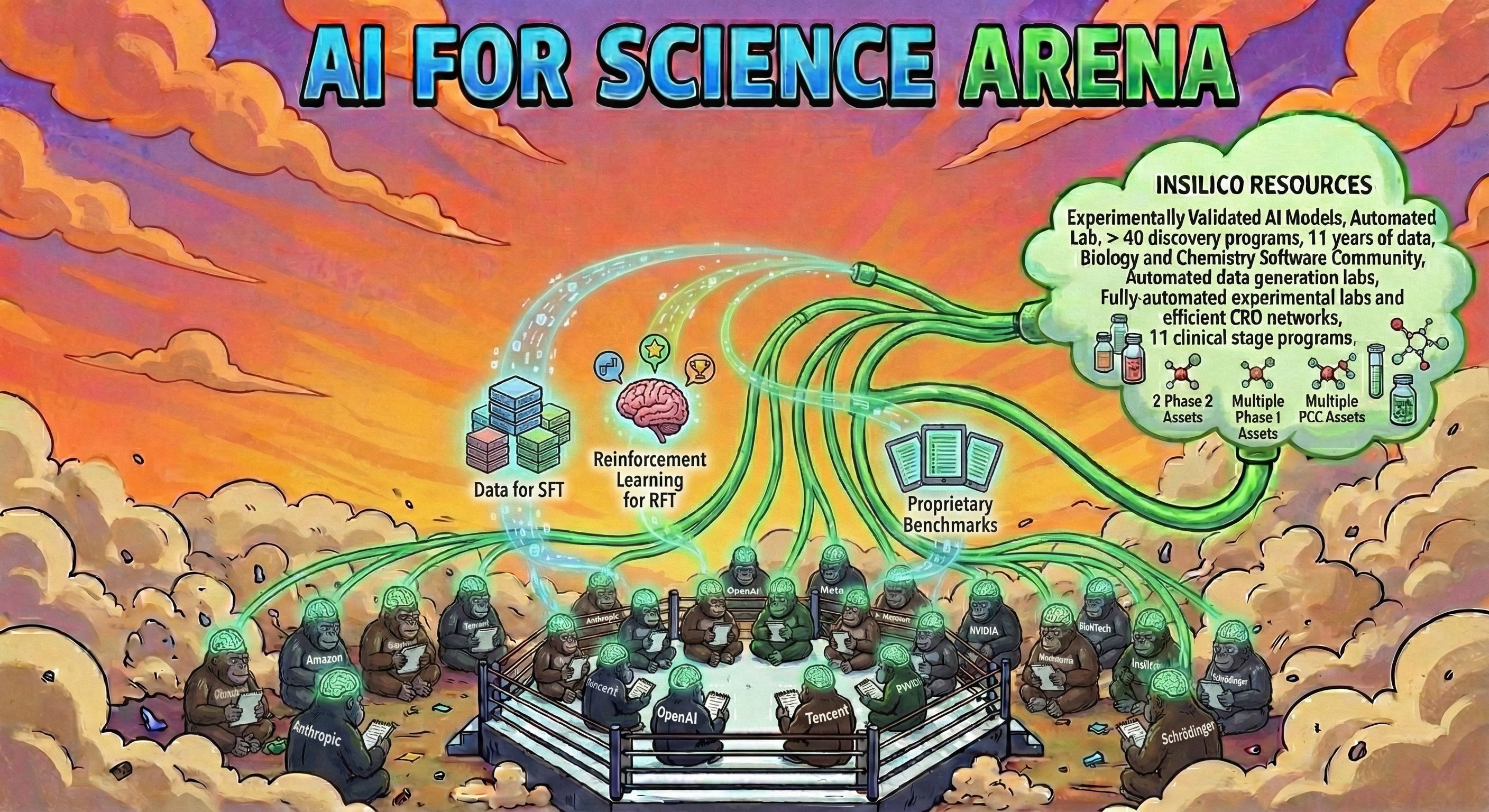
The NeurIPS Debut and the Varying Rates of Interest
We unveiled the preliminary results of this work and the concept of the MMAI Gym at the “Virtual Cells & Instruments” workshop at NeurIPS in December. Following this, we sent proposals to the top foundation model developers, inviting them to bring their models to our gym.
The response revealed an interesting geopolitical divergence in the AI race.
We saw immediate and intense interest from Asia. The ecosystem there is hungry for differentiation and application-level dominance. Developers in China and the surrounding region moved fast, eager to integrate scientific reasoning into their models to leapfrog competitors.
In contrast, US developers were slower to respond. This was partly due to the holiday season lag, but it also highlighted a structural disconnect. Many “AI for Science” teams in Western Big Tech are surprisingly isolated from the rapid pace of their own frontier model development. They are often siloed, working on older architectures or disconnected from the “trenches” of real-world drug discovery.
However, as we moved into January 2026, the sleeping giants awoke. They are catching up now, realizing that generalist capabilities alone will not suffice for the scientific breakthroughs that justify their valuations.
The Race for the “Bio-Phys-Chem-Med Foundation”
It is now becoming clear that every major foundation model developer is pivoting toward science. They are pushing ahead with massive teams dedicated to drug discovery. They understand that the next trillion-dollar opportunity lies not in advertising or chatbots, but in solving the fundamental biology of aging and disease.
However, most of these developers are flying blind.
We recently met with a frontier developer-an absolute leader in hardware and software-and realized they were practically clueless about how drug discovery works in the trenches. They didn’t understand the rigorous process of going from a target hypothesis to a developmental candidate, nor the safety hurdles involved. They focus on tiny, isolated problems like protein folding, thinking they are solving “biology,” while missing the massive orchestration required to develop a therapeutic asset.
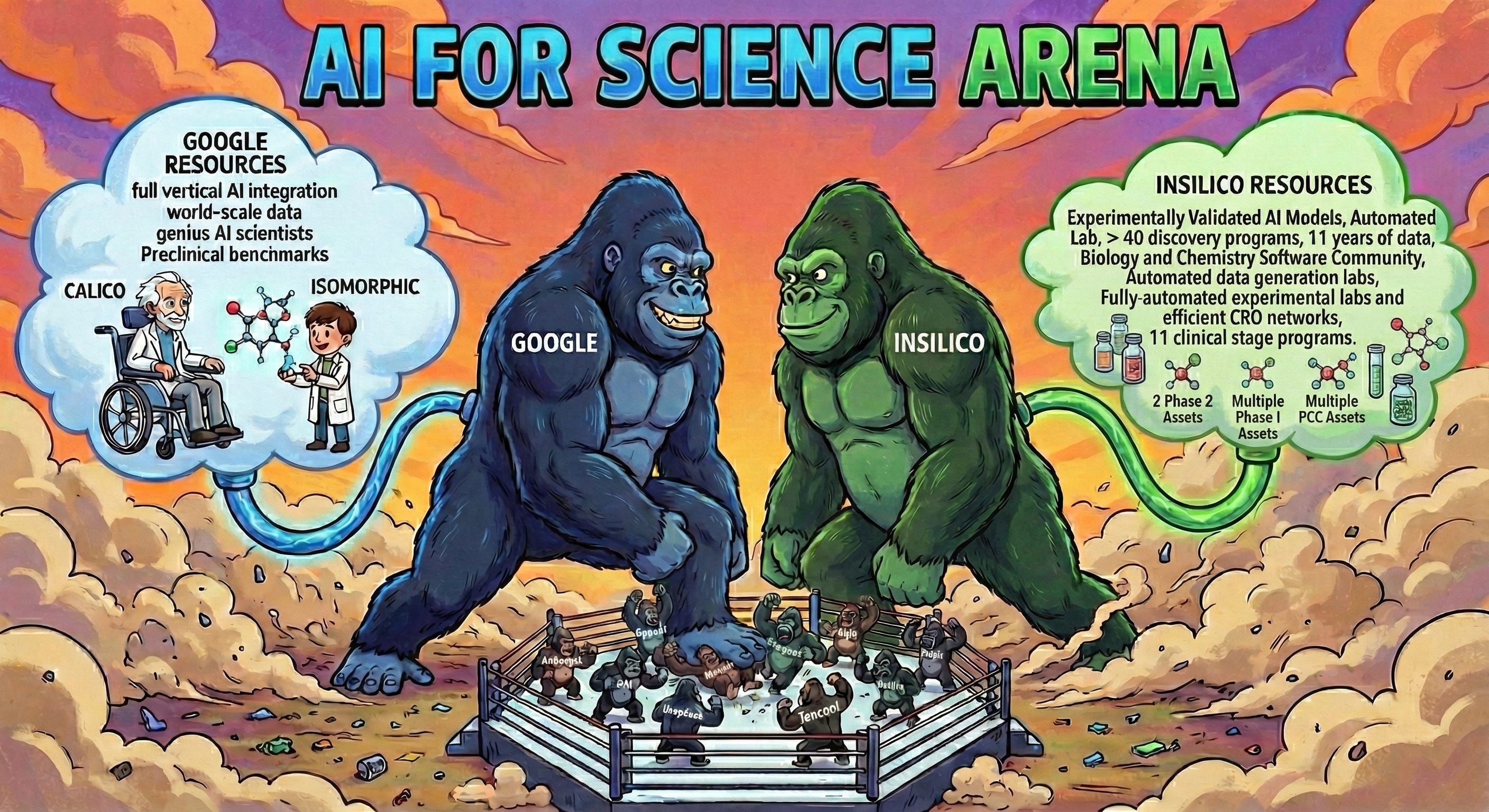
The Google Dominance
In this chaotic landscape, only one tech giant has truly figured out AI for science: Google.
They realized that you cannot build a valid AI for drug discovery without running your own therapeutic programs and established their own drug discovery company. Actually, two companies, Calico, which was not productive so far but probably generated data and infrastructure, and Isomorphic Labs, which is moving full-speed ahead with their own internal pipeline.
You need “ground truth.” You need to know if the molecule your AI designed actually binds to the target, if it is toxic in a rat, if it is stable in human liver microsomes. Google understood that they needed to generate their own proprietary data from the trenches to validate their models. This closed-loop capability-AI prediction followed by wet-lab validation-is the only way to establish real benchmarks and improve model performance.
Other companies in the AI space, AWS, Microsoft or Nvidia, do not have this advantage - without real drug discovery programs they can not really see the results of their drug discovery platforms in the end-to-end fashion and do not have the real-world benchmarks to evaluate their performance. This is the problem we are trying to solve with the MMAI Gym - it will allow frontier model developers to compete with Google and other model developers that figured out the experimental and clinical side of drug discovery.
The MMAI Gym is built on years of hard work in drug discovery and experimental science:
We have nominated 27 developmental candidates.
We have received IND clearance for multiple molecules.
We successfully completed Phase IIa clinical trials for our lead program in Idiopathic Pulmonary Fibrosis (IPF).
We have our own automated robotics lab, Life Star 2, which runs 24/7 generating biological data.
We have over 1,000 proprietary benchmarks derived from these real programs. When we train a model in the MMAI Gym, we are testing it against data that cost millions of dollars and years of human effort to generate. This is the difference between an AI that plays a video game of science, and an AI that does actual science.
2026: The Year of Pharmaceutical Superintelligence
I predict that 2026 will be the year of benchmarks, AI for science, and the emergence of true superintelligence in this domain.
We are moving toward a future where a researcher can sit in front of a prompt window and orchestrate an entire drug discovery campaign-from target identification to the design of small molecules and biologics, to the planning of preclinical and clinical studies. This concept, which we call “Chemical and Biological Superintelligence” (CSI and BSI), is within reach.
By the end of this year, we expect to see models that are not just “helpful assistants” but superhuman agents capable of reasoning through complex biological pathways, predicting clinical trial outcomes with high accuracy (as we saw with our >0.90 F1 scores), and designing molecules that are successful on the first attempt.
The winners in this space will be defined by who has the best data and the most rigorous training environments.
Check out our recent conversation with the brilliant CEO of Owkin, Dr. Thomas Clozel.
A Note of Caution: Do Not Expect Magical Cures from AI in 5 Years
Despite this optimism, we must remain grounded in the brutal economic and scientific realities of our industry.
In practical drug discovery, we should not expect miracles.
There remains a profound disconnect between theoretical science (what the AI predicts) and experimental reality (what happens in the human body). A single, tiny molecular modification can lead to dramatic differences in toxicity or efficacy. An AI model might find a perfect binder that may also cause some liver tox in 1% of the population. For a a drug targeting a chronic disease or a biological process like obesity, even this small number will not be acceptable.
The costs are astronomical. A single therapeutic program can still cost roughly a billion dollars to carry through to completion.
Commercial tractability still rules. A drug must not only work; it must be patentable, manufacturable at scale, and reimbursable by insurance. Most importantly, investors and the pharmaceutical companies that will be developing it, must believe in this drug to invest. This limits the number of novel targets AI companies can go after.
AI can accelerate the early stages-we have cut the time to preclinical candidate nomination from 4.5 years to as little as 9 months-but it cannot yet cheat the biology of the human body or the regulatory requirements of clinical trials. The “trenches” are deep, and the fight against disease is long.
The Open MMAI Gym Model
This is why Insilico has decided to open our doors. We developed the MMAI Gym for ourselves, to gain an edge in this difficult war against disease. But now, we are opening this gym to foundation model vendors.
We want to act as the coach for the frontier model developers, helping them test and train their models on real-world scientific tasks. We are creating a hybrid of ScaleAI and a specialized scientific laboratory. By providing access to our 1,000+ benchmarks, our proprietary data (including 1 billion+ data points with 3D poses and 100 million+ reactions), and our automated wet lab validation, we aim to level the playing field.
We believe that in the future, frontier foundation model developers will take over the majority of drug discovery tasks. Our goal is to ensure they do it right. To ensure that the “superintelligence” they build is grounded in the reality of chemistry and biology, not just the patterns of text.
The next battlefield is here. Welcome to the MMAI Gym for Science.
Disclaimer: This article is written with the help of generative tools so beware of hallucinations. The images were generated using NanoBanana. Don’t buy, sell, or take any drugs based on this article or any of its contents. The information and views expressed in this article are for informational and educational purposes only and do not constitute medical advice. The content is not intended to be a substitute for professional medical advice, diagnosis, or treatment. Always seek the advice of your physician or another qualified health provider with any questions you may have regarding a medical condition. Never disregard professional medical advice or delay in seeking it because of something you have read in this article. The author is sharing personal experiences and opinions. These experiences are not a recommendation or endorsement for any specific treatment, drug, or course of action. The medications and therapeutic strategies discussed may not be suitable for everyone and can have significant risks and side effects. Some of the drugs mentioned are investigational and have not been approved by the FDA or other regulatory agencies for the uses discussed. While the author is the CEO of Insilico Medicine, the statements and view presented in Forver.ai do not represent the views and opinions of Insilico Medicine.
Go, Insilico, go! We are fortunate to have such an intelligent, forward-looking company on our side, and who can deny Alex's excellent leadership?